A Database for Corpus-Assisted Critical Discourse Analysis
In addition to the workshops being conducted in Lebanon and the “Hate to Hope” Massive Open Online Course, Project SOMEONE is developing a database to critically analyze online discourses related to themes and topics of interest to Lebanon and its neighbours. The database is intended to contribute to decision- and policy-making by researchers and public policy officials, as well as contributing to social action, counter-terrorism narratives and related practice by practitioners and community leaders internationally. The database will increase knowledge of patterns of online hate, extremism, misogyny and gender-based violence, and their uses for researchers, public policy officials, practitioners, and community leaders in the Lebanese context. The database will be available online in spring 2019 to our partners and other interested parties.
The first step of the database project has been to identify instances of online conversations that exemplified typical discourses around topics related to political discussions, social or cultural commentary, discussions around gender and human rights, entertainment etc. In collaboration with our partners in Lebanon, discussions were identified on popular online spaces such as YouTube, Twitter, Facebook and Reddit. The identified discussion threads were collected and then parsed to extract the conversation content, as well as metadata such as the topic of the conversation, the number of comments or up votes a post had and so on. The result was two databases – one in English and the other in Arabic. The researchers then identified additional threads on the same online spaces, with the same topics. The resultant corpus size was ready for analysis.
Corpus-Assisted Critical Discourse Analysis (CACDA) allows for rigorous analysis of large volumes of electronically encoded data by combining conventionally quantitative corpus linguistic techniques with typically qualitative critical discourse analytic methods. In other words, it helps uncover patterns in the naturally occurring discourses among people and applies critical analysis to those patterns.
The English database was further analyzed by platform. The Reddit database, had 445,861 words, while the YouTube database had 247,184 words. The Arabic database contained data from Facebook and YouTube and had 784,058 words.
From the initial analysis completed so far, the researchers have identified nearly 50 words that not only appear in high frequency but show statistical significance in terms of the logdice index. Some of these words (along with their variations) are Refugees, Immigrants, Women, America, Hezbollah, Hate, Muslim, Jew.
The identified keywords collocate significantly with words which will form the basis for the next round of analysis. A sample of these collocations are refugee… crisis, women… rights, illegal… immigrants, Jew… hate, Hezbollah… missile, Lebanese… army, terrorist… America and so on.
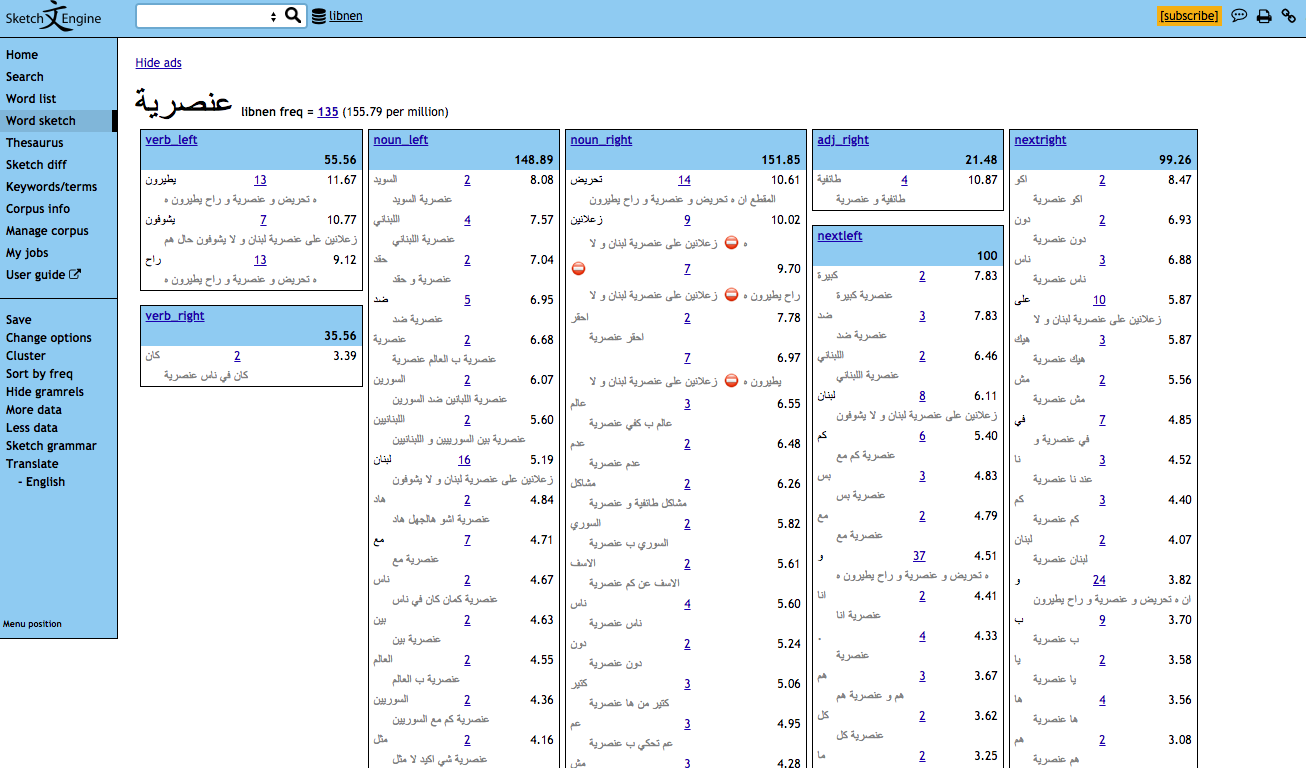
This screenshot shows a word sketch of the word Onsuriyye, “Prejudice”. The numbers in black are the logdice values associated with the respective collocations (words).
In the next phase of the analysis, a detailed qualitative analysis will be undertaken to review the specific contexts in which these collocations occur. Each of these collocations will be studied in the context of the topic and the platform in which it was said. The project expects that such a study will potentially offer insight into how these words have been used in Lebanon-related discussions in the past year.