Une base de données pour analyser le discours critique assistée par corpus
Outre les ateliers organisés au Liban et le cours en ligne ouvert et massif (CLOM) « De la haine à l’espoir », le projet SOMEONE développe une base de données pour analyser de manière critique les discours en ligne sur des thèmes et sujets qui intéressent le Liban et ses voisins. Cette base de données a pour objectif de contribuer à la prise de décision et à la formulation de politiques par les chercheurs et les responsables des politiques publiques, ainsi qu’à l’action sociale, les récits contre le terrorisme et aux pratiques des praticiens et des dirigeants locaux au niveau international. La base de données augmentera la connaissance des tendances de la haine en ligne, de l’extrémisme, de la misogynie et de la violence sexospécifique et la façon dont celles-ci seront utiles pour les chercheurs, les responsables des politiques publiques, les praticiens et les dirigeants communautaires dans le contexte libanais. La base de données sera disponible en ligne au printemps 2019 pour nos partenaires et les autres parties intéressées.
La première étape du projet de base de données a été d’identifier des exemples de conversations en ligne illustrant des discours typiques sur des sujets liés aux discussions politiques, aux commentaires sociaux ou culturels, aux discussions sur les questions de genre et les droits humains, aux divertissements, etc. En collaboration avec nos partenaires au Liban, des discussions ont été repérées sur des réseaux sociaux populaires tels que YouTube, Twitter, Facebook et Reddit. Les fils de discussion identifiés ont été rassemblés, puis analysés pour extraire le contenu de la conversation, ainsi que des métadonnées telles que le sujet de la conversation, le nombre de commentaires ou de critiques positives d’un message, etc. Le résultat était deux bases de données – une en anglais et l’autre en arabe. Les chercheurs ont ensuite trouvé des fils supplémentaires sur les mêmes sujets et réseaux sociaux. La taille du corpus obtenue était maintenant prête à analyser.
L’analyse critique du discours assistée par corpus (Corpus-Assisted Critical Discourse Analysis ou CACDA) permet une analyse rigoureuse de grands volumes de données codées électroniquement en combinant des techniques généralement quantitatives de la linguistique de corpus, avec des méthodes typiquement qualitatives d’analyse du discours critique. En autres mots, cela aide à découvrir des tendances dans les discours spontanés des gens et à leur appliquer une analyse critique.
La base de données anglaise a ensuite été analysée en fonction de chaque plateforme individuelle. Celle de Reddit comptait 445 861 mots, tandis que celle de YouTube en possédait 247 184. La base de données arabe contenait des données de Facebook ainsi que YouTube et englobait 784 058 mots.
À partir de l’analyse initiale réalisée jusqu’à présent, les chercheurs ont identifié près de 50 mots qui apparaissent fréquemment et qui présentent également une signification statistique en termes d’indice logDice. Certains de ces mots (de même que leurs variations) sont : réfugiés, immigrés, femmes, Amérique, Hezbollah, haine, musulman, juif.
Les mots-clés identifiés coïncident de manière significative avec des mots qui constitueront la base du prochain cycle d’analyse. Un échantillon de ces collocations sont : réfugié … crise, femmes … droits, illégal … immigrants, juifs … haine, Hezbollah … missile, libanais… armée, terroriste… Amérique, etc.
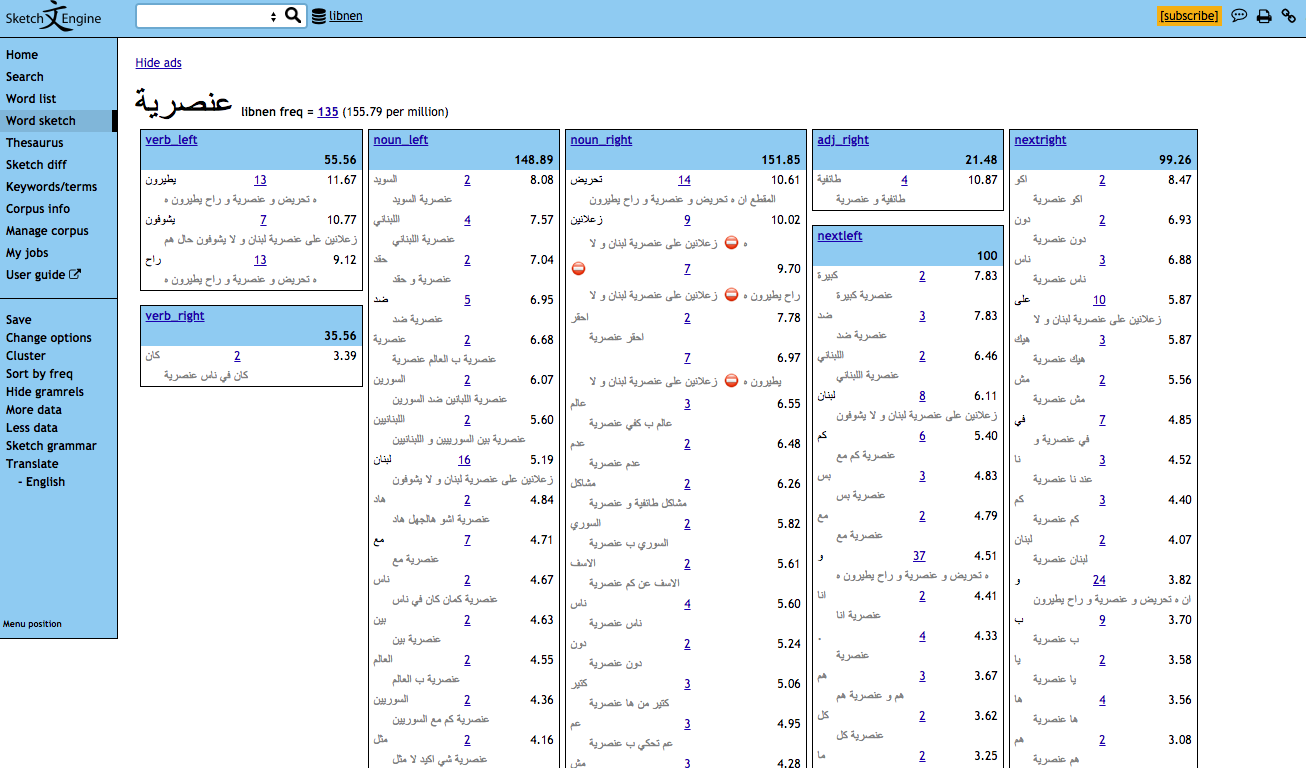
Cette capture d’écran montre une esquisse du mot Onsuriyye, « préjudice ». Les nombres en noir sont les valeurs de logDice associées aux collocations respectives (mots).
La prochaine phase comprendra une analyse qualitative détaillée afin d’examiner les contextes précis dans lesquels ces collocations se produisent. Chacune de celles-ci sera étudiée dans le cadre du sujet et de la plateforme de sa provenance. Le but de ce projet est qu’une étude de ce genre offre un aperçu de la manière dont ces mots ont été utilisés dans les discussions relatives au Liban au cours de la dernière l’année.